|
Hi, I'm Gaurav. I am a PhD student at University of Maryland, Baltimore County advised by Prof. Nirmalya Roy. My research focuses on embodied AI and collaborative perception for robotic systems. Previously, I worked as a Research Assistant at MiCoSys Lab with Prof. Saptarshi Sengupta, where I developed deep learning techniques for predicting the remaining useful life of lithium-ion batteries. LinkedIn / Google Scholar / GitHub / CV Currently seeking a summer internship to apply my expertise in robotics, embodied AI, & computer vision to solve real-world problems. |

|
||||||||||||||||||||||||||||||||||||
Recent News
|
|||||||||||||||||||||||||||||||||||||
|
|
|
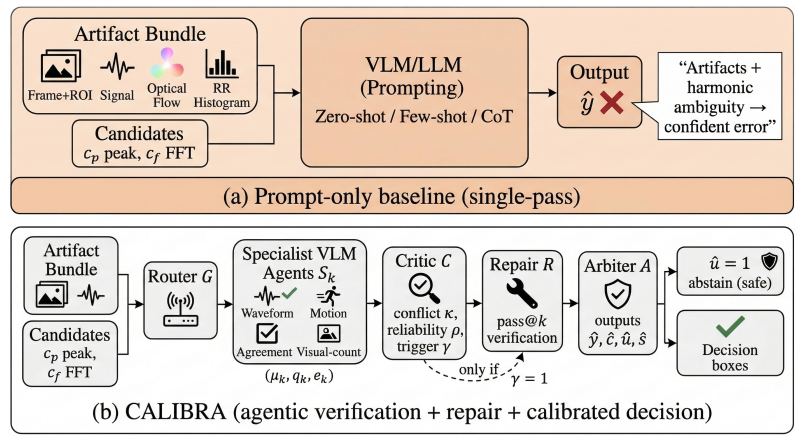
Shadman Sakib, Gaurav Shinde, Nirmalya Roy CVPR GRAIL-V, 2026 paper Contactless physiological monitoring offers a promising path toward low-burden health sensing, but reliable infer- ence from short video segments remains difficult when vi- sual evidence is weak, corrupted by motion, or spectrally ambiguous. We present CALIBRA, a calibration-aware multi-agent framework for contactless respiratory rate (RR) estimation that treats prediction as an evidence-grounded verification problem rather than a one-shot prompting task. The framework operates on a structured artifact bundle with lightweight signal-derived candidate rates, and per- forms routing, specialized vision-language evidence analy- sis, critic-based consistency checking, targeted repair, and calibrated arbitration with optional abstention. On our in- house benchmark, it consistently outperforms prompting- only baselines across multiple backbones. With Gemini-2.5- Flash, it reduces mean absolute error (MAE) from 5.21 to 3.42, corresponding to a 34.4% reduction over zero-shot prompting and a 16.8% reduction over chain-of-thought prompting. With GPT-4o, it reduces MAE from 5.48 to 3.78, a 31.0% reduction over zero-shot prompting. It also im- proves grounding and consistency in judge-based evalua- tion, indicating better evidence alignment beyond numeri- cal accuracy alone. Under resource constraints, a routed configuration maintains 93% coverage at 4.1 s average la- tency and 1.6 GB peak memory. These results show that robust contactless physiological inference depends not only on stronger multimodal backbones, but also on explicit ver- ification of whether predictions are supported by the avail- able evidence. |
|
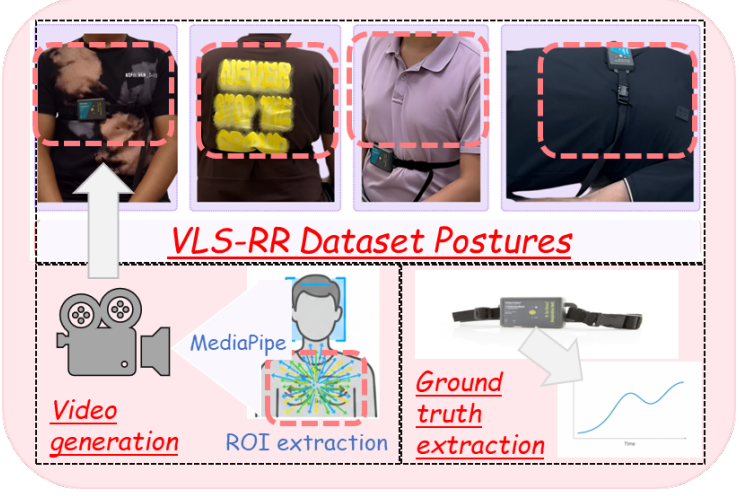
Shadman Sakib, Gaurav Shinde, Nirmalya Roy IEEE/ACM CHASE, 2026 paper Contactless respiratory monitoring from video is a promising alternative to wearable sensors but remains sensitive to motion artifacts and variations in viewpoint and lighting, which degrade the reliability of respiratory rate (RR) estimates. Traditional signal processing methods often struggle to separate physiological motion from visual artifacts, while large multimodal models (LMMs) can reason about these artifacts but are often too computationally demanding for privacy-sensitive or embedded deployments. This work aims to improve robustness and deployability by explicitly decoupling visual perception from downstream reasoning. We propose VLS-RR (Visual–Language– SLM Respiratory Rate) auditor, a three-stage framework where video segments are converted into fused motion signals and summary plots. A vision–language model (VLM) then produces a textual description of rhythm, breath count, and artifacts. Finally, small language models (SLMs) perform chain-of-thought (CoT) auditing over this evidence and the signal-derived RR candidates. We evaluate VLS-RR on a 50-video belt-synchronized dataset spanning diverse breathing patterns, viewpoints, and lighting conditions. Compared with signal-only baselines, VLS-RR reduces segment-level MAE by ≈ 30% and improves R 2 from 0.85 to 0.92. It also outperforms numeric-only SLM baselines with an additional ≈ 25% MAE reduction. Finally, on an embedded edge device, compact SLM auditors run with 0.82–1.71 s latency per 6 s window, indicating that decoupling perception and reasoning enables accurate, resource-efficient RR estimation from video. |

|
Emon Dey, Anuradha Ravi, Gaurav Shinde, Garvit Chugh, Indrajeet Ghosh, Archan Misra, Nirmalya Roy IEEE PerCom, 2026 paper Federated Learning (FL) enables collaborative machine learning across decentralized devices and data sources, but resource constraints on pervasive devices necessitate efficient model compression. Existing approaches, such as quantization for on-device training, often degrade accuracy, especially for classes that are difficult to learn due to imbalance, poor-quality samples, or inherent complexity. This results in persistent accuracy gaps across classes. We propose Fed-CASQ’s a novel framework that couples class-aware strategies into the quantization process to jointly improve efficiency and accuracy in pervasive FL. Unlike prior works that address quantization and imbalance separately, Fed-CASQ adaptively selects quantization levels based on device resources and leverages Layer-wise Relevance Propagation (LRP) to assess class-relevant convolutional neural network (CNN) filters on the client side. An adaptive weight scaling mechanism is then applied to amplify critical information for low-accuracy classes before aggregation. At the server, a complementary novel aggregation strategy mitigates global imbalance across clients, ensuring that underperforming classes receive proportional attention during model updates. We empirically establish that quantization directly influences the performance of under sampled (minority) classes. Experimental results further show that Fed-CASQ substantially narrows the performance gap for low-accuracy classes, improving their accuracy by ≈30%, while reducing training latency by over 56% on resource-constrained pervasive devices. |
|
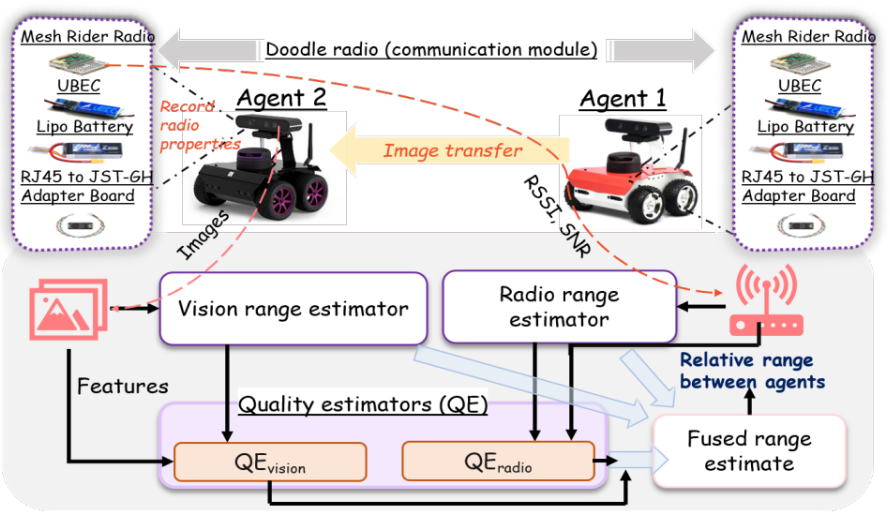
Gaurav Shinde, Anuradha Ravi, Jared Lewis, Andre Harrison, Henry Gardiner, MS Anwar, Shadman Sakib, Jade Freeman, Nirmalya Roy IEEE WoWMoM, 2026 paper In mission-critical scenarios, autonomous agents often operate in GPS-denied or GPS-degraded environments, making it chal- lenging to localize agents relative to themselves and objects of interest (e.g., potential cover) or adversarial robots. While vision- and radio- based modalities have individually been used to estimate relative ranges between agents and surrounding objects, each modality suffers from in- herent limitations. Vision-based range estimation degrades significantly under low image overlap, partial visibility, or when an agent is too close to an object, resulting in effective zoom-in and loss of geometric context. Conversely, radio-based ranging is susceptible to multipath interference, signal fading, and environmental variability, which can substantially reduce range accuracy and reliability. To address these challenges, we introduce CAViAR, a quality-aware multimodal fusion framework for ac- curate relative range estimation among collaborative autonomous agents. CAViAR assigns modality-specific reliability scores and performs sta- tistical fusion to adaptively weigh vision and radio inputs based on their estimated quality. The framework employs modality-specific quality estimators augmented with temporal features and integrates MBConv blocks to enable efficient feature processing on resource-constrained robotic platforms. We validate CAViAR on ROSbot 2 and ROSbot 2 Pro platforms using an in-house dataset collected across diverse indoor and outdoor environments. Experimental results demonstrate that our approach outperforms single-modality baselines by approximately 21% over vision-only and 36% over radio-only range estimates. Moreover, CAViAR adapts robustly to variations in scene structure, viewpoint overlap, and occlusions without requiring fine-tuning on new environments, highlighting its practicality for real-world deployment. |
|
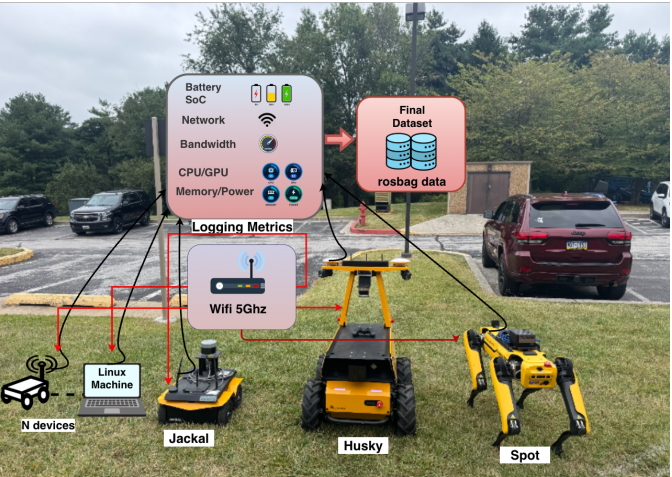
MS Anwar, Anuradha Ravi, Indrajeet Ghosh, Gaurav Shinde, Carl Busart, Nirmalya Roy IEEE WoWMoM, 2026 paper Large deep neural networks (DNNs), especially transformer-based and multimodal architectures, are computationally demanding and challenging to deploy on resourceconstrained edge platforms like field robots. These challenges intensify in mission-critical scenarios (e.g., disaster response), where robots must collaborate under tight constraints on bandwidth, latency, and battery life, often without infrastructure or server support. To address these limitations, we present COHORT, a collaborative DNN inference and taskexecution framework for multi-robot systems built on the Robotic Operating System (ROS). COHORT employs a hybrid offline–online reinforcement learning (RL) strategy to dynamically schedule and distribute DNN module execution across robots. Our key contributions are threefold: (a) Offline RL policy learning combined with Advantage-Weighted Regression (AWR), trained on auction-based task allocation data from heterogeneous DNN workloads across distributed robots, (b) Online policy adaptation via Multi-Agent PPO (MAPPO), initialized from the offline policy and fine-tuned in real time, and (c) comprehensive evaluation of COHORT on vision-language model (VLM) inference tasks such as CLIP and SAM, analyzing scalability with increasing robot/workload and robustness under . We benchmark COHORT against genetic algorithms and multiple RL baselines. Experimental results demonstrate that COHORT reduces battery consumption by 15.4%, and increases GPU utilization by 51.67%, while satisfying framerate and deadline constraints 2.55x of the time. |
|
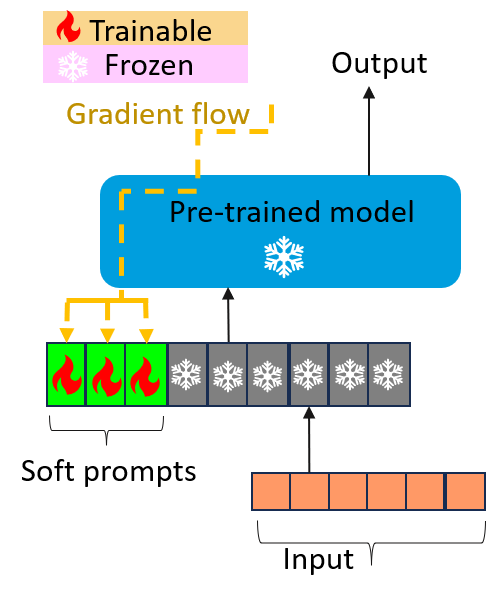
Gaurav Shinde, Anuradha Ravi, Emon Dey, Shadman Sakib, Milind Rampure, Nirmalya Roy WIREs DMKD, 2025 paper Vision-language models (VLMs) integrate visual and textual information, enabling a wide range of applications such as image captioning and visual question answering, making them crucial for modern AI systems. However, their high computational demands pose challenges for real-time applications. This has led to a growing focus on developing efficient vision language models. In this survey, we review key techniques for optimizing VLMs on edge and resource-constrained devices. We also explore compact VLM architectures, frameworks and provide detailed insightsinto the performance-memory tradeoffs of efficient VLMs. |

|
Shadman Sakib, Gaurav Shinde, Emon Dey, Nirmalya Roy IEEE SmartComp, 2025 paper Continuous, non-invasive respiratory rate (RR) monitoring is essential for the early diagnosis of many medical problems. However, conventional contact-based sensors frequently under-perform in dynamic situations that can be uncomfortable and require human intervention. To overcome these limitations, we propose E2RespUNet, an end-to-end system that uses multimodal video data to estimate breathing rates and reconstruct respiratory signals using an attention-enhanced U-Net architecture. Our method combines optical flow analysis with preprocessing, detrending, and normalization to reliably extract chest motion features in a variety of settings. According to our study in both the temporal and frequency domains, E2RespUNet surpasses existing baseline models by lowering the mean absolute error by up to 21 % in the sleep dataset and by up to 28% in the in-house dataset. |
|
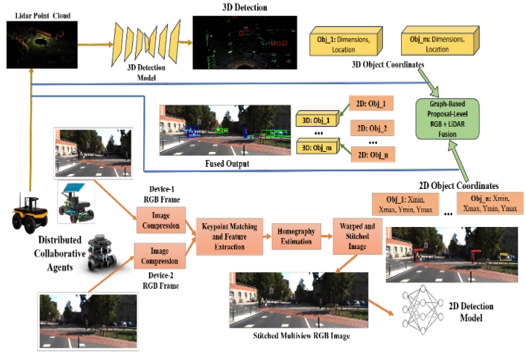
MS Anwar, Anuradha Ravi, Emon Dey, Gaurav Shinde, Indrajeet Ghosh, Jade Freeman, Carl Busart, Andre Harrison, Nirmalya Roy IEEE DECOSS-IoT, 2025 paper Integrating multimodal data such as RGB and LiDAR from multiple views significantly increases computational and communication demands, which can be challenging for resource-constrained autonomous agents while meeting the time-critical deadlines required for various mission-critical applications. To address this challenge, we propose CoOpTex, a collaborative task execution framework designed for cooperative perception in distributed autonomous systems (DAS). |
|
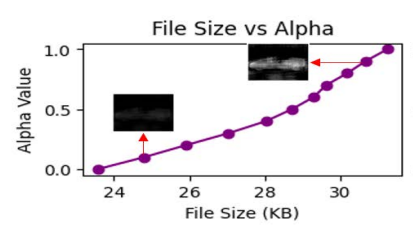
Gaurav Shinde, Anuradha Ravi, Emon Dey, Jared Lewis, Nirmalya Roy IEEE PerCom Worshop, 2025 paper In network-constrained environments, distributed multi-agent systems—such as UGVs and UAVs—must communicate effectively to support computationally demanding scene perception tasks like semantic and instance segmentation. These tasks are challenging because they require high accuracy even when using low-quality images, and the network limitations restrict the amount of data that can be transmitted between agents. To overcome the above challenges, we propose TAVIC-DAS to perform a task and channel-aware variable-rate image compression to enable distributed task execution and minimize communication latency by transmitting compressed images. TAVIC-DAS proposes a novel image compression and decompression framework (distributed across agents) that integrates channel parameters such as RSSI and data rate into a task-specific "semantic segmentation" DNN to generate masks representing the object of interest in the scene (ROI maps) by determining a high pixel density needed to represent objects of interest and low density to represents surrounding pixels within an image |
|
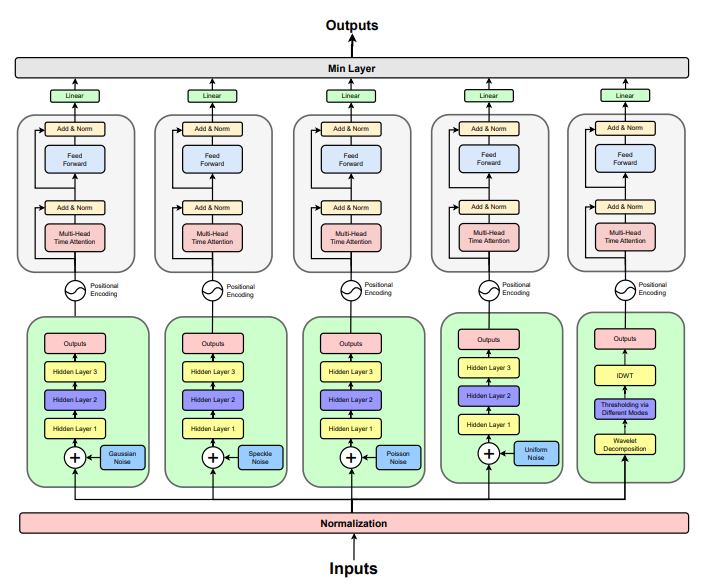
Gaurav Shinde, Rohan Mohapatra, Pooja Krishan, Saptarshi Sengupta IEEE BigData, 2023 paper The usage of Lithium-ion (Li-ion) batteries has gained widespread popularity across various industries, from powering portable electronic devices to propelling electric vehicles and supporting energy storage systems. A central challenge in Li-ion battery reliability lies in accurately predicting their Remaining Useful Life (RUL), which is a critical measure for proactive maintenance and predictive analytics. This study presents a novel approach that harnesses the power of multiple denoising modules, each trained to address specific types of noise commonly encountered in battery data. Specifically, a denoising auto-encoder and a wavelet denoiser are used to generate encoded/decomposed representations, which are subsequently processed through dedicated self-attention transformer encoders. After extensive experimentation on NASA and CALCE data, a broad spectrum of health indicator values are estimated under a set of diverse noise patterns. The reported error metrics on these data are on par with or better than the state-of-the-art reported in recent literature. |
Website adapted from Jon Barron